Tech Tips
Word Embeddings and Embedding Models in Machine Learning
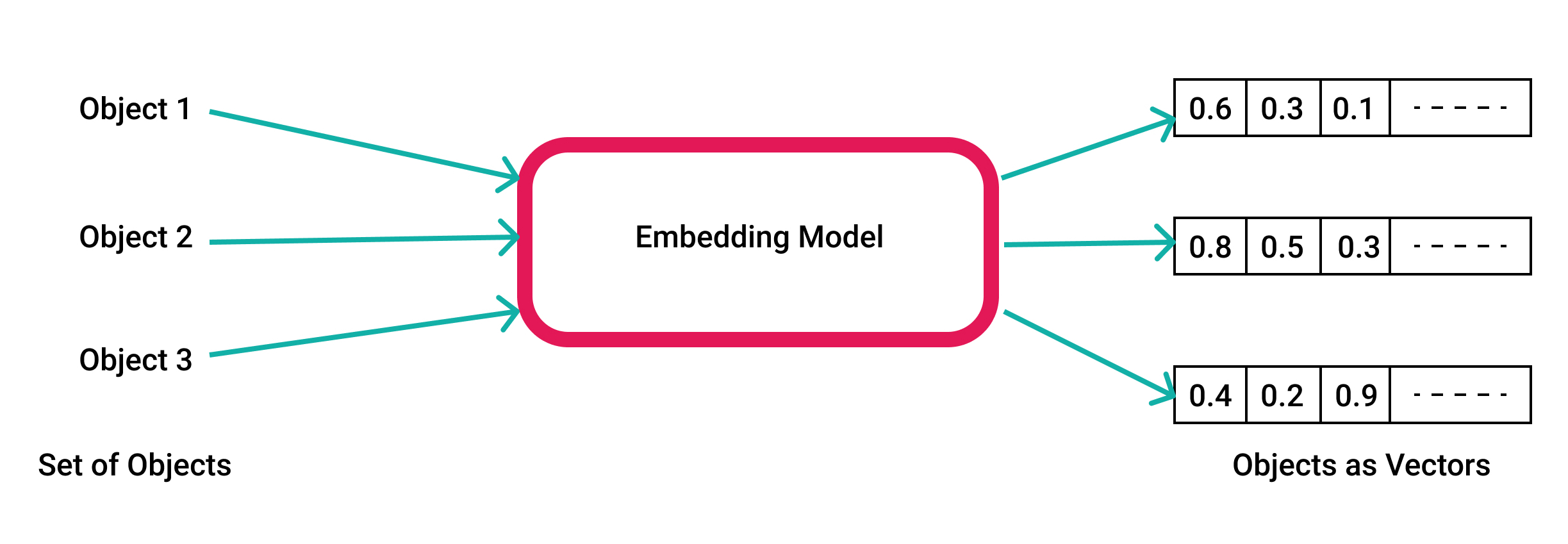
In this article, you will be reading and getting to know about what are word embeddings, what are embedding models, what are word embeddings and embedding models in machine learning? What are its features, services, importance, etc. below you will be learning about these in explicit detail.
What do you mean by Word Embeddings?
Documents and words can be represented by this approach. Word Embeddings or we can say Word Vectors are known as numeric vector inputs which work as representing a word in a lower dimensional space. It also gives approval to the words which have almost the same meanings and have almost the same representation. It can also have almost accurate meanings.
What are its features?
Anything which would relate words with each other word. Eg: Time, Games, Gym, Working etc. and many more. Every word vector search has its values which correspond to these given features.
What are its uses?
- It is commonly used as an input to all the machine learning models.
- Keep these words in mind —-> Given its numeric representation —-> which is being used in the training process or inference.
- In order to represent it or to visualize it by any taken patterns of its usage in the corpus which earlier was being used to train them perfectly.
What are benefits of the usage of Word Embeddings:
- The process is much quicker to prepare than the hand-built models such as WordNet (which generally use graph embeddings).
- Most modern type NLP applications begin with the uniqueness of the embedding layer.
- It usually keeps an exact approximation of the rare meaning.
Limitations of Word Embeddings:
- It could be storage bound.
- It is highly corpus inter-dependent. Any underlying bias would create an effect on the model.
- It could not briefly differentiate between the homophones itself.
What are the Embedding Models?
Embedding models are the kinds of knowledge representation in which every textual variable is to be represented by a vector (let’s think of it as a point of numbers for now). A textual variable could be a word of knowledge, node form in a graph or a related typo between the two nodes form in a knowledge graph. These vector searches can be named by multiple different words such as space search vectors, latent database vectors, or an embedding vector database.
This vector search often represents a multi-dimensional space feature on which machine learning methods can be applied very easily. Therefore, there is an urgent need to make a sudden shift into how we could think about the language from a set of words to the points that will occupy a very high-dimensional semantic space where all the points in space that can be close together or far apart depending on it.
What is their need?
The main motive of this representation process is to file out words with almost the same meanings (which are utmost semantically related to each other) in order to have almost the same representation process and to be a little closer to each other after the plotting process of them in a space. And why do you think that would ever be important here? Well, for many things, mainly because:
- As you may know, computers do not really or completely understand the text and the relationship between the words, so you might need a way out to use these words with a numeral or a number which a computer can easily understand.
- Embedding models can also be used in many other applications you may know such as question/answer systems, recommendation systems, sentimental analysis, text classifications and it can also work by making it easier to search or to return synonyms perfectly.
What do you mean by Word Embedding in Machine Learning?
In order to completely convert the text of the data into numerical data, we would need some really smart ways which are commonly known as vectorization, or apparently in the NLP world, it is often known as Word Embeddings. Coming later on, those vector searches could be easily used to build many numbers or style or design of machine learning models.
In this very way, we can freely say that this is an amazing feature working with the great help of text and with an indigenous aim to build a great multiple natural languages, processing models, etc. Let us just now define this term, Word Embeddings, formally as Word Embedding usually tries to map a word best using a dictionary to its vector database form. Broadly, we can classify these word embeddings into the following two categories:
- First, Frequency-based Word Embedding or Statistical based Word Embedding.
- Second, Prediction-based Word Embedding.
What do you mean by Embedding Models in Machine Learning?
Embedding models are now considered very hard numeral representation for the real-world objects, systems and relationships, which is clearly expressed as a vector search. The vector space expresses the semantic similarity between categories so deeply. Embedding model vectors that are usually fitted very close to each other are considered almost the same.
Sometimes, they can also be used directly for the “Similar objects to this” part for an e-commerce store section. In other times, embeddings can be passed to other models. In all of those cases, the embedding model can easily share learnings all across all the same to the same items rather than creating those as two entirely different categories, as it is the similar case with the one-hot encodings visible.
For this very reason, embedding models can be used efficiently to particularly show sparse data just like clickstreams, texts, and e-commerce purchases as the features it shows to the downstream models. On the other hand, you will notice that embeddings are very much more costly to compute rather than those one-hot encodings and those are far less interpretable than the others.
Also, in order to perfectly create a word embedding, BERT takes into the account of the context of consideration of the word. Which actually means that the word “play” in “I’m going to play football” and “I want to see that play” would have different embeddings. BERT has now become the go-to transformer model for the great work of generating text embeddings around the world.

Top 5 Benefits of Hiring Reliable House Cleaners in Melbourne

How to Remove Personal Data from Data Brokers

Bridging the Gap: Challenges and Solutions for Multilingual Events in KenyaBridging the Gap: Challenges and Solutions for Multilingual Events in Kenya

How to Choose the #1 Ranked Phone Data Service Platform

Affordable Virtual Assistant

Effective WordPress Maintenance and Brand Revamping: Key Strategies for Success

iPhone 15 Pro Max Price in Pakistan: A Comprehensive Review

Exotic Escapes: Unveiling the Most Exclusive Villas in North Goa

Earn Profits with Ellyx P2P Cryptocurrency Exchange

Top Small Business Bank Accounts in the UK: Find Your Perfect Fit Today
-

 Blog1 year ago
Blog1 year agoMyCSULB: Login to CSULB Student and Employee Portal – MyCSULB 2023
-

 Android App3 years ago
Android App3 years agoCqatest App What is It
-

 Android1 year ago
Android1 year agoWhat Is content://com.android.browser.home/ All About in 2023? Set Up content com android browser home
-

 Software2 years ago
Software2 years agoA Guide For Better Cybersecurity & Data Protection For Your Devices
-
Latest News2 years ago
Soap2day Similar Sites And Alternatives To Watch Free Movies
-
Android2 years ago
What is OMACP And How To Remove It? Easy Guide OMACP 2022
-
Android3 years ago
What is org.codeaurora.snapcam?
-
Business2 years ago
Know Your Business (KYB) Process – Critical Component For Partnerships










